Dask presentation and tutorials
2026
What is Dask ?
![]()
Python library for parallel and distributed computing
- Scales Numpy, Pandas and Scikit-Learn
- General purpose computing/parallelization framework
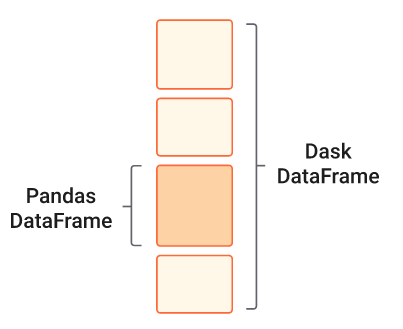
Dataframes
- Extends Pandas library
- Enables to parallelize Pandas Dataframes operations
- Similar to Apache Spark
import pandas as pd
df = pd.read_csv("file.csv")
result = df.groupby(df.name).amount.mean()import dask.dataframe as dd
df = dd.read_csv("file.csv")
result = df.groupby(df.name).amount.mean()
result = result.compute() # Compute to get pandas resultArrays
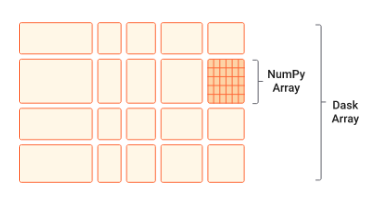
- Extends Numpy library
- Enables to parallelize Numpy array operations
import numpy as np
x = np.random.random((10000, 10000))
y = (x + x.T) - x.mean(axis=1)import dask.array as da
x = da.random.random((10000, 10000))
y = (x + x.T) - x.mean(axis=1)Delayed
- Allow to construct custom pipelines and workflows
- Enables to parallelize arbitrary for-loop style Python code
- Parallelize and distribute tasks
- Lazy task scheduling
- Similar to Airflow
from dask.distributed import LocalCluster
client = LocalCluster().get_client()
# Submit work to happen in parallel
results = []
for filename in filenames:
data = client.submit(load, filename)
result = client.submit(process, data)
results.append(result)
# Gather results back to local computer
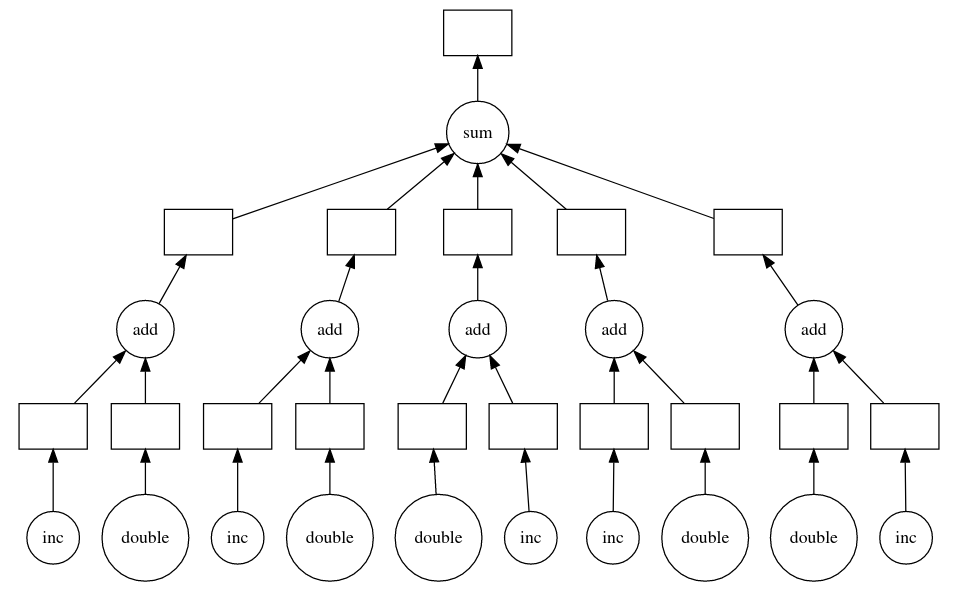
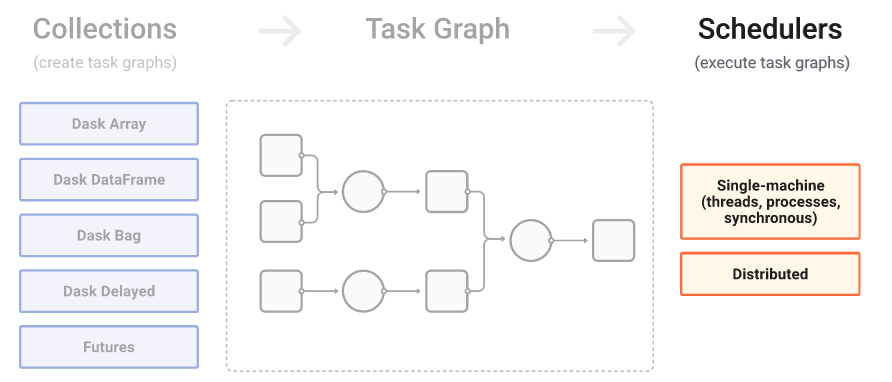
results = client.gather(results)First, produce a task graph
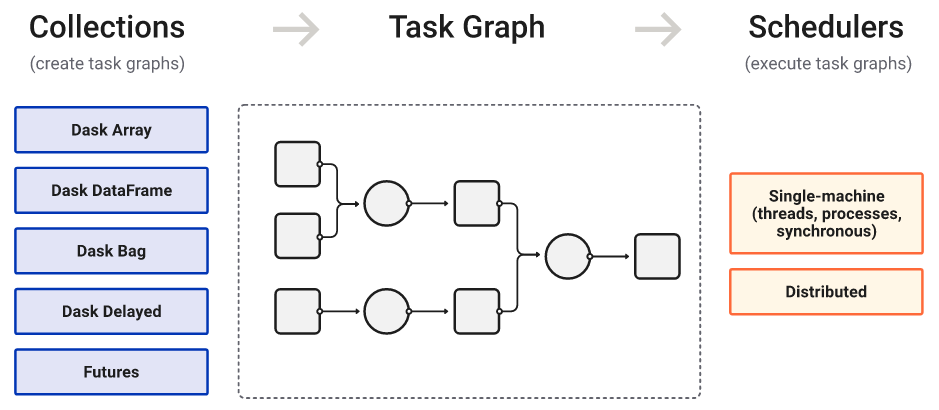
High level collections are used to generate task graphs
First, produce a task graph
Create an array of ones
import dask.array as da
x = da.ones(15, chunks=(5,))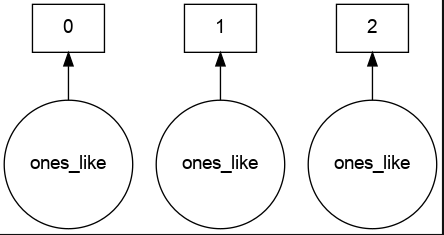
First, produce a task graph
Sum that array
import dask.array as da
x = da.ones(15, chunks=(5,))
y = sum()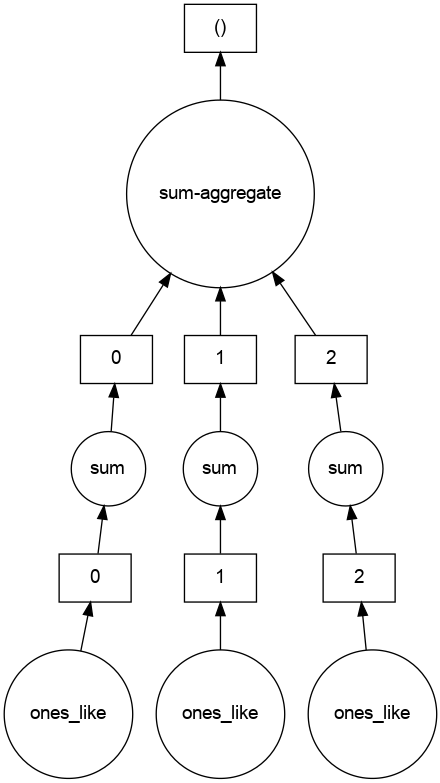
First, produce a task graph
Create an 2d-array of ones and sum it
import dask.array as da
x = da.ones((15,15), chunks=(5,5))
y = x.sum()
First, produce a task graph
Add array to its transpose
import dask.array as da
x = da.ones((15,15), chunks=(5,5))
y = x +x.T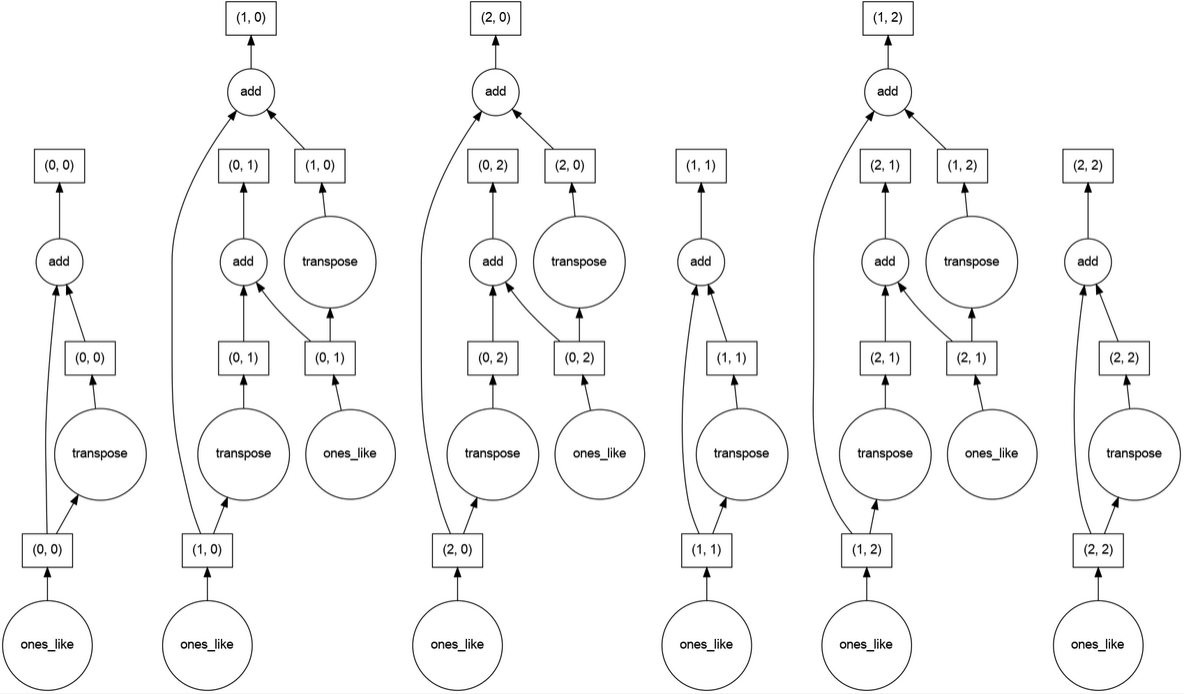
First, produce a task graph
Matrix multiplication
import dask.array as da
x = da.ones((15,15), chunks=(5,5))
y = da.ones((15,15), chunks=(5,5))
r = da.matmul(x,y)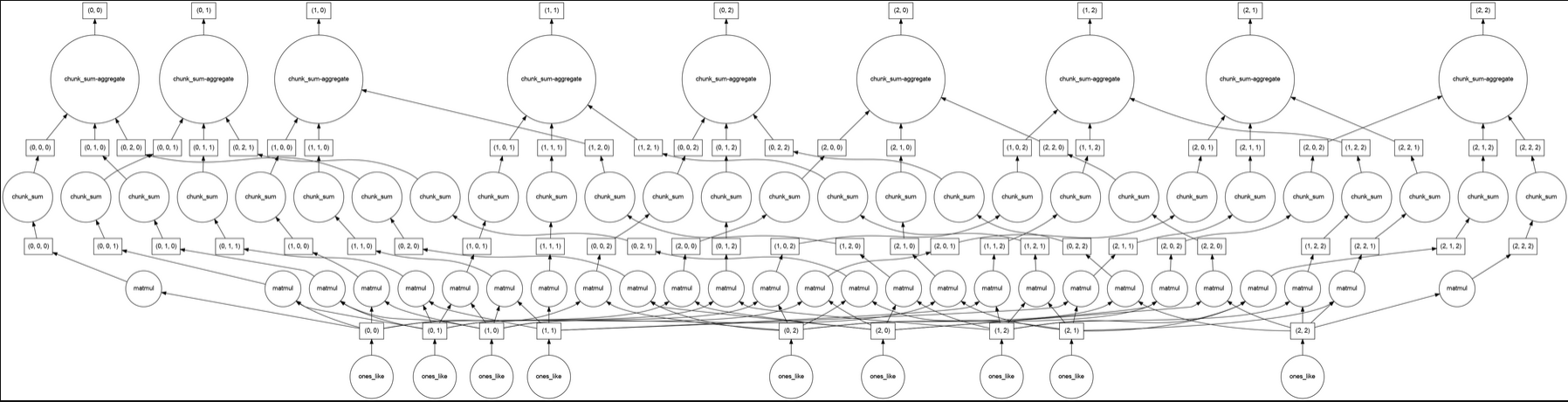
Dask graph
import dask.array as da
x = da.ones((15,15), chunks=(5,5))
y = da.ones((15,15), chunks=(5,5))
r = da.matmul(x,y)x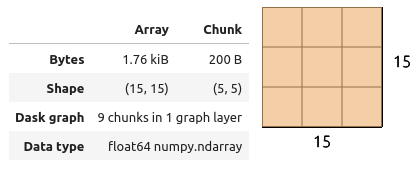
Then, compute the calculation
Use compute() to execute the graph and get the
result
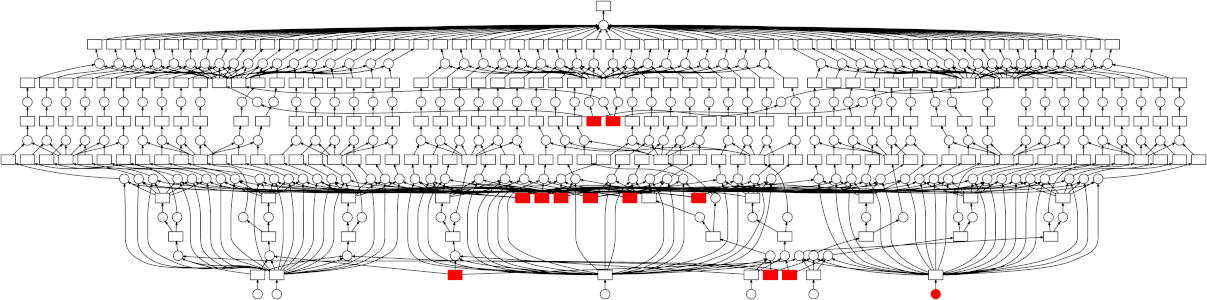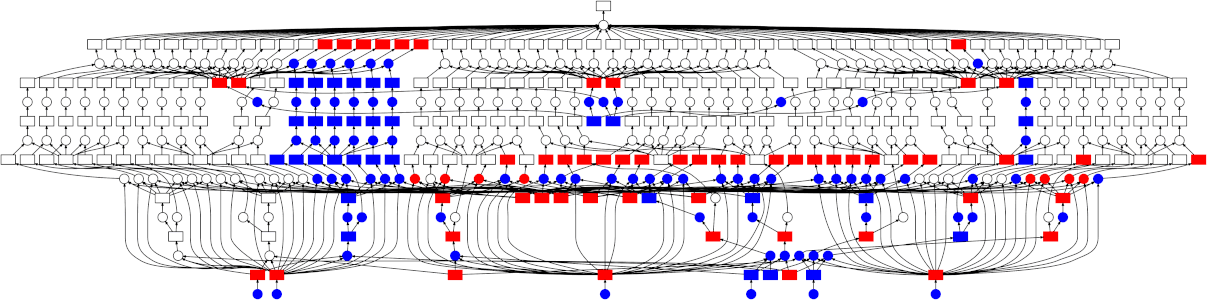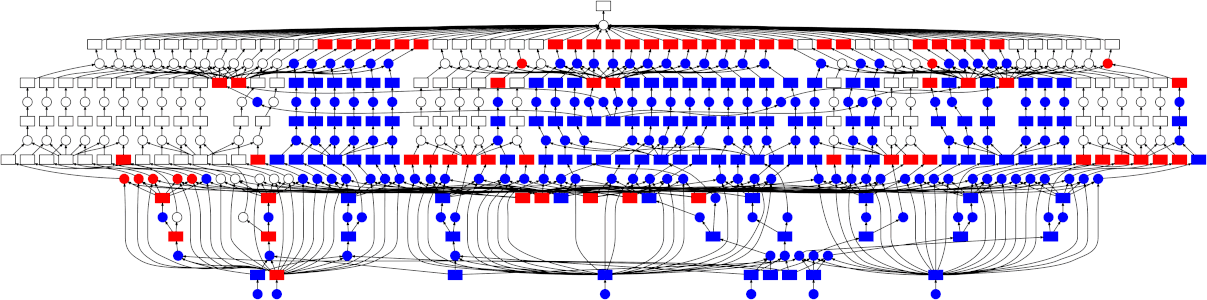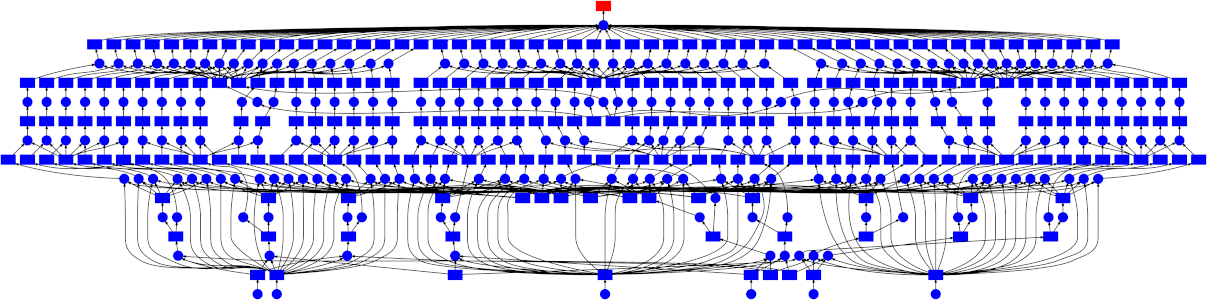
Dask execution
- Task graphs can be executed by schedulers on a single machine or a cluster
- Dask offers several backend execution systems, resilience to failures
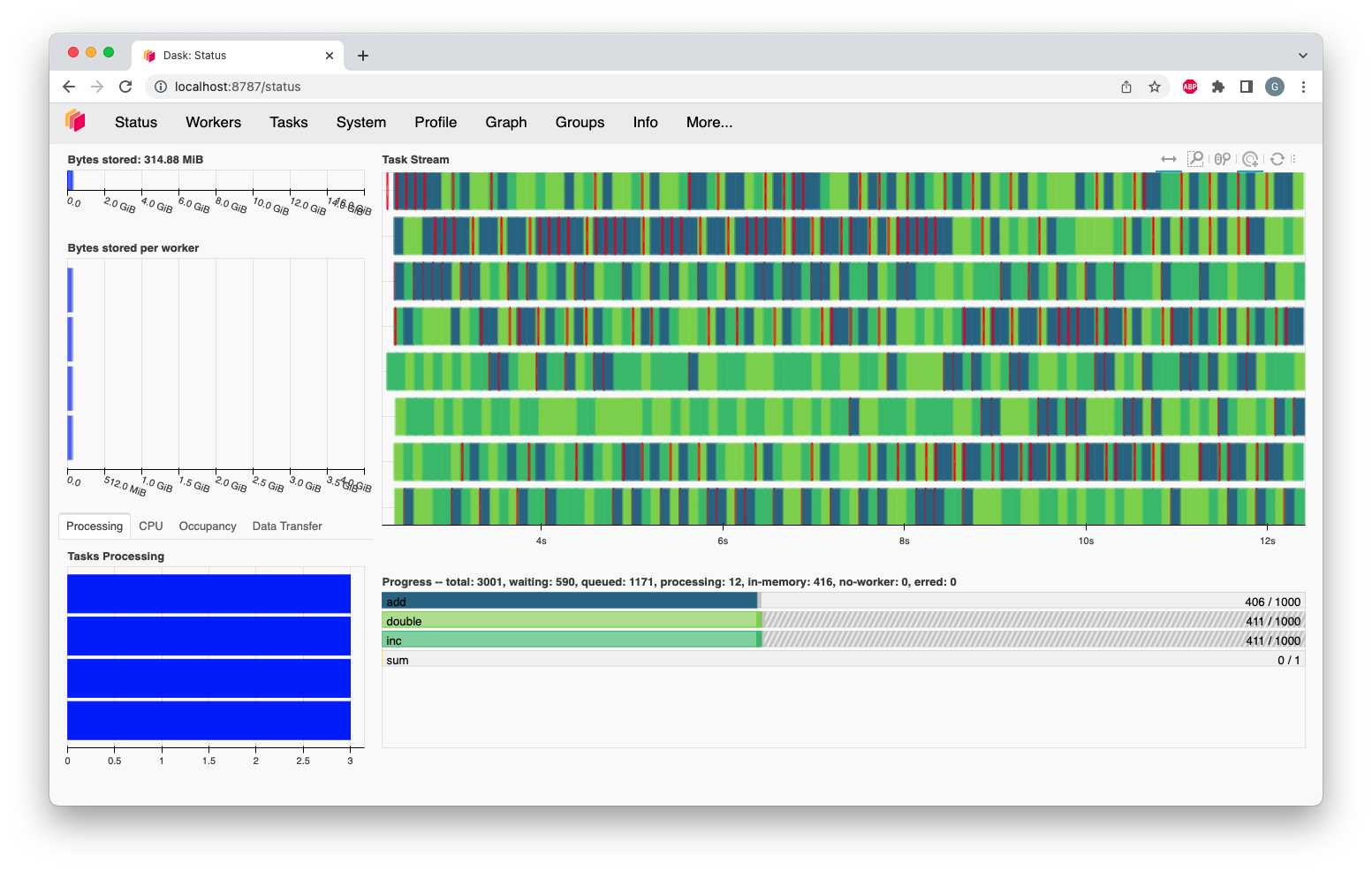
Dask execution

Use Dashboard
- Help to understand the state of your workers
- Follow worker memory consumption
- Follow CPU Utilization
- Follow data Transfer between workers
Scikit-learn/Joblib
model = Model(...,n_jobs=n)
model.fit(X,y)- User specify n_jobs
- Scikit-learn and joblib communicate
- Joblib uses threads and processes on a single machine

Scikit-learn/Joblib/Dask
from joblib import parallel_backend
model = Model(...,n_jobs=n)
with parallel_backend("dask"):
model.fit(X,y)- User specify n_jobs
- Scikit-learn and joblib communicate
- Joblib and Dask communicate
- Dask distributes jobs
