Manage large datasets
2026
More and more data
Process ever larger and more numerous datasets
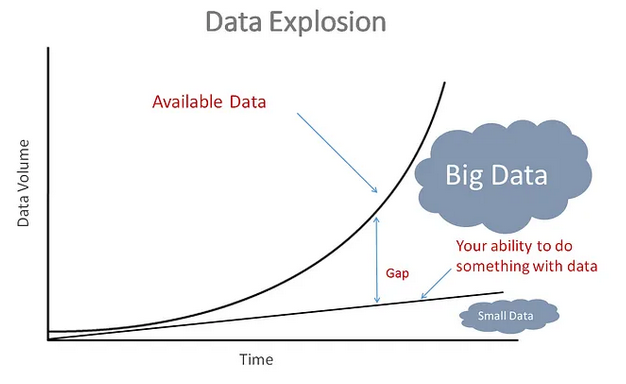
https://towardsdatascience.com/machine-learning-with-big-data-86bcb39f2f0b
Apache parquet
![]()
- Free and open-source column-oriented data storage format
- Provides efficient data compression and encoding schemes
- Designed for long-term storage
- Can be use on distributed data storage
- Supported by an extensive software ecosystem with multiple frameworks and tools
Feather
![]()
- Free and open-source column-oriented data storage format
- More intended for short term or ephemeral storage
- Support two fast compression libraries, LZ4 and ZSTD
- Can be use on distributed data storage
- Less popular than parquet so the number of supporting frameworks is much more limited
AVRO
![]()
- Free and open-source raw-oriented data storage format
- Not supported natively by pandas
- Relies on schemas
Zarr
![]()
- Free and open-source
- Array oriented file format
- File storage format for chunked, compressed, N-dimensional arrays
- Same performances than HDF5
- More flexible because chunking can be done along any dimension
- Cloud optimized