Python for Distributed Processing
2026
Numba

Numba makes Python code fast
- Translates Python functions to optimized machine code at runtime (Just In Time compilation)
- Use LLVM compiler library
- Python can approach the speeds of compiled languages like C or FORTRAN
- Just apply one of the Numba decorators
from numba import jit
import random
@jit(nopython=True)
def monte_carlo_pi(nsamples):
acc = 0
for i in range(nsamples):
x = random.random()
y = random.random()
if (x ** 2 + y ** 2) < 1.0:
acc += 1
return 4.0 * acc / nsamplesJoblib
![]()
- Set of tools to provide lightweight pipelining in Python
- transparent disk-caching of functions and lazy re-evaluation (memoize pattern)
- easy simple parallel computing
- Optimized to be fast and robust on large data
from math import sqrt
from joblib import Parallel, delayed
Parallel(n_jobs=2)(delayed(sqrt)(i ** 2) for i in range(10))
[0.0, 1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, 9.0]Dask
![]()
- Provides advanced parallelism for analytics
- First designed as allowing to process datasets bigger than memory
- Now from local computer to clusters, to HPC or Cloud computing
- Scales Numpy and Pandas with same interfaces
- More low level APIs for distributing any algorithm
- More tomorrow

import dask.dataframe as dd
df = dd.read_csv('2014-*.csv')
df.describe().compute()PySpark

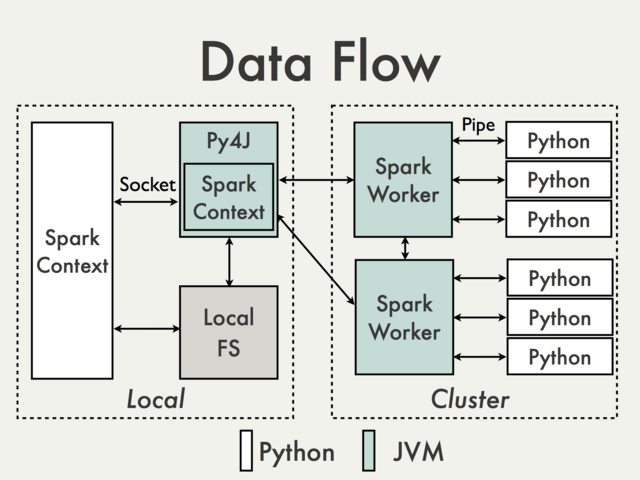
- Spark is Scala (JVM based), but for data scientists, provides Python and R interface
- This means some complexity and translation between languages
Others
Parallelization with deep learning framework
- Parallelization for hyper-parameter optimization with Ray Tune
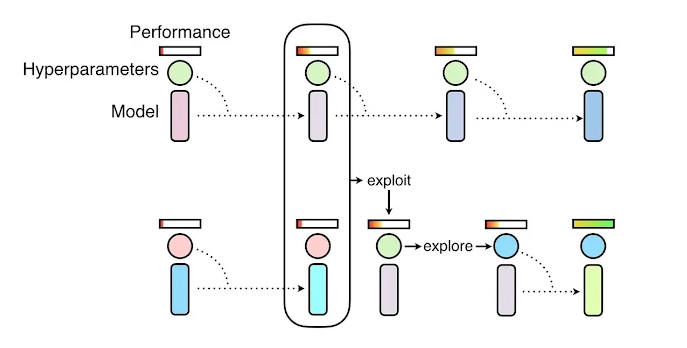
Population based training of neural networks (Deepmind)